Supported by QMUL & DeepMind
“How can synchronization between audio and visual be achieved in a multiple-speaker scene (e.g., Zoom)?”
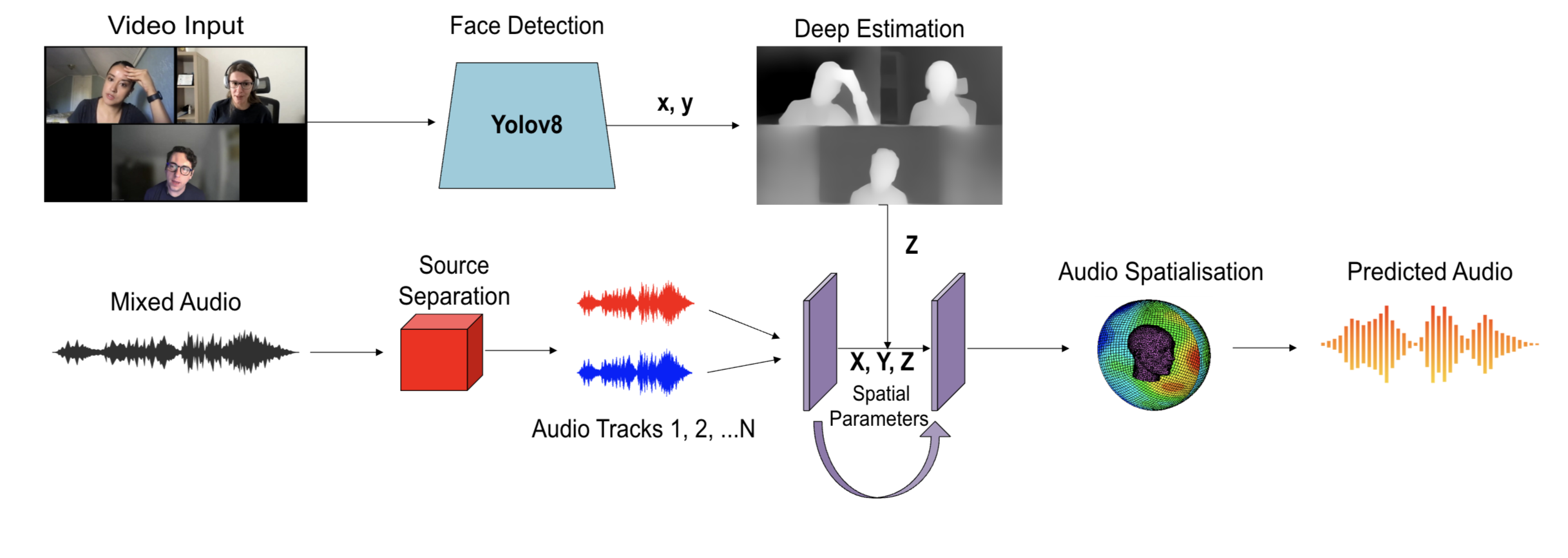
Yolov8
We utilize YOLOv8 to obtain information from the X and Y axes.
Depth Estimation
We use depth estimation to extract information along the Z axis.
Spatial Audio Generation
Through HRTF convolution and 3D algorithm implementation.
- Present our work in QMUL!